Scrapy学习笔记
作者:Kirino 联系方式: he-jx19@mails.tsinghua.edu.cn
Scrapy是一个常用的Python爬虫框架,主要由Spider、Engien、Scheduler和Downloader组成。运行机制如下图所示
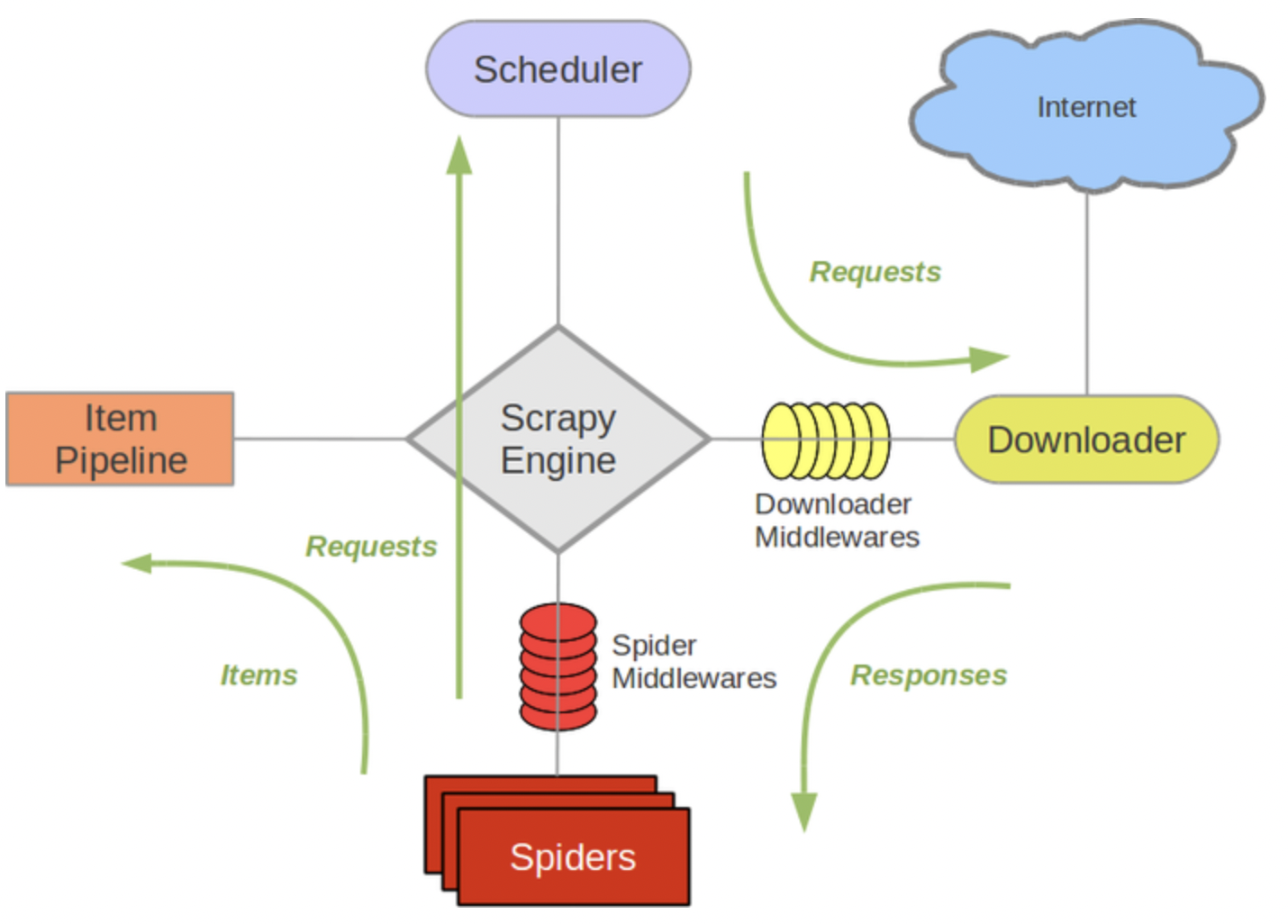
Spider发出请求(包括目标url、请求体等),经过中间件包装后发送到Engine。Engine再把请求派发给Scheduler,Scheduler按照任务队列的形式,将请求经中间件处理后调用Downloader下载请求资源。在Spider拿到响应,解析资源后可以交给Item Pipeline进行进一步处理。
安装方法
直接使用pip安装即可
查看是否安装成功
最小程序
以从https://www.thss.tsinghua.edu.cn/szdw/jsml.htm爬取得软件学院所有老师和所属研究所为例。
新建项目
在当前的项目文件夹下执行下面的命令,新建一个scrapy项目。
之后,会出现一个以mySpider为名的文件夹。在mySpider/spider/文件夹下,我们就可以定义我们的sipder。
定义Spider
一只最简单的spider需要继承scrapy的抽象基类scrapy.Spider,定义name和要爬取的url,然后实现parse方法。parse方法会作为请求成功后的默认回调,处理响应。
例如,我先把网页内容爬取并保存
# spider/thss_spider.py
class ThssSpider(scrapy.Spider):
name = "thss"
start_urls = ['https://www.thss.tsinghua.edu.cn/szdw/jsml.htm']
def parse(self, response, **kwargs):
page = response.url.split("/")[-2]
filename = f'thss-{page}.html'
with open(filename, 'wb') as f:
f.write(response.body)
self.log(f'Saved file {filename}')
运行Spider
使用下面的指令可以通过指定spider name启动对应的spider
实际上,在启动spider后,Engine会遍历start_urls,隐式地调用下面的代码
即向对应的url发送请求并收到响应后,实例化一个Response对象,并且调用parse方法进行解析。
当然,我们也可以显式地调用上面的代码,只需要在Spider类中实现start_request方法即可。
运行后,我们得到了一个新增文件thss-szdw.html,里面就保存了https://www.thss.tsinghua.edu.cn/szdw/jsml.htm的网页内容。
<!DOCTYPE html>
<html data-n-head-ssr>
<head>
<title>教师名录-清华大学软件学院</title><META Name="keywords" Content="清华大学软件学院,教师名录" />
...
</html>
Scrapy还提供一个交互式的shell,通过运行
scrapy shell 'https://www.thss.tsinghua.edu.cn/szdw/jsml.html'即可打开。在这个shell里,可以通过response变量访问到我们请求的响应。
定义数据结构
我们想要得到每位老师以及对应的研究所,Scrapy下的item pipline为我们提供了方便的数据存储功能。在myScrapy/items.py中,定义了我们自己的Item类,继承自scrapy.Item。它可以通过data1 = scrapy.Feild()的方式定义结构化数据字段,与Dict类似,但是提供了更好的封装。
在这里,我们保存教师名和所属研究所
数据解析
我们需要对抓取下来的网页结构先进行人工分析。分析可发现,与教师-机构相关的部分呈现下面的结构。
<div class="group-title">某个研究所</div>
<div class="group-people">
<div class="name-container"><a>老师1</a></div>
<div class="name-container"><a>老师2</a></div>
</div>
Scrapy.Response类提供了通过css选择器进行查询的方法。若在Scrapy Shell中,我们可以直接通过response.css('css selector')的方法进行选择。注意,.css()会返回一个子选择器(列表),我们可以通过在子选择器上调用.get()方法查看选择到的内容。也可以把这个选择器保存下来,再进行进一步选择。
以上面的数据为例,选择研究所可以通过div.group-title。因为不止一个研究所,因此会返回一个列表。我们可以查看第一项
发现把整个div标签都返回了回来。如果我们只想要标签中包裹的内容,可以在选择时指定::text
接下来,我们获取每个研究所下的老师。这一步,我们就需要先通过div.group-people获得所有研究所的子选择器列表,然后把列表中的每一项保存起来,即是一个研究所的子选择器。之后,再在这个选择器上通过a标签获得老师名字。
>>> ins2 = response.css('div.group-people')[1]
>>> ins2.css('a::text').getall()
['罗贵明', '顾明', '向东', '覃征', '罗平', '赵曦滨', '邓仰东', '贺飞', '张荷花', '万海', '周旻', '高跃', '姜宇']
按上面的方法,我们就获得了软件系统与工程研究所所有老师的姓名。
保存数据
接下来,我们只需要将获得的数据储存到定义好的数据结构MyscrapyItem中即可。为此,我们需要在thss_spider.py文件中引入MyscrapyItem,同时需要再将上面的信息储存在一个列表中。
from myScrapy.items import MyscrapyItem
def parse(self, response, **kwargs):
items = []
institutions = response.css('div.group-title::text').getall()
for i, institution in enumerate(institutions):
teachers = response.css('div.group-people')[i].css('a::text').getall()
for teacher in teachers:
item = MyscrapyItem()
item['name'] = teacher
item['institution'] = institution
items.append(item)
return items
导出数据
Scrapy支持我们将爬取到的数据以.json, .jsonl, .csv, .xml四种格式保存。只需要在爬虫命令后加上-o指令,后跟输出文件名即可。
例如,我们可以以csv格式导出
在Excel或者Numbers中打开,则可以看到下面的结果
